
This article delves into the implementation of an Industrial Internet of Things (IIoT) project involving machine learning at a large locomotive repair facility undergoing digital transformation. The project’s aim was to accurately track the number of locomotives and their precise positions within the facility. This was achieved by strategically deploying IP cameras, due to the large size of the locomotives and the layout of the facility. The focus of the article is not on the machine learning methods used, but rather on the evolution from a monolithic application to a microservices architecture and its benefits.
The project unfolded in several stages:
-
Proof of Concept (PoC): A monolithic Python application was developed to process video streams from all cameras, determine the positions of the locomotives, and estimate the state of the facility. Despite its initial success, the application faced stability issues.
-
Microservices Transition: The application was broken down into microservices, including video stream capture, image aggregation, locomotive position estimation, and facility state estimation, enhancing flexibility and scalability.
-
Data Flows: The data was integrated into a cloud solution for storage and real-time analysis, improving the feedback loop for development and operational teams.
-
Extensibility: New requirements emerged, leading to the development of additional microservices for recognizing locomotive models and ‘plate numbers’.
The article concludes by highlighting the advantages of microservices over monolithic architecture in complex IIoT projects, emphasizing the importance of flexible data flow management and the ability to adapt to new requirements.
Stage #1: PoCPermalink
The initial phase of the project involved developing a robust monolithic Python application with several key functionalities:
- Streaming Video Data: The application was designed to receive and process live video streams from multiple cameras installed throughout the facility. This step was crucial in capturing real-time visual data of the locomotives at various repair stations.
- Locomotive Position Analysis: The core functionality centered around analyzing each video feed to determine whether the locomotive’s head or tail was in view for each camera. This was a challenging task due to the limited field of view of each camera and the large size of the locomotives.
- Facility State Estimation: By integrating the positional data from all camera feeds, the application could generate a comprehensive estimation of the entire facility’s state. This involved mapping out the location and orientation of each locomotive within the facility, providing a dynamic and updated view of operations.
To manage the computationally intensive tasks, the application was dockerized and deployed on a server equipped with a powerful GPU. Utilizing the NVIDIA Container Toolkit, the team ensured optimal utilization of the GPU resources for processing the video streams and executing the machine learning algorithms efficiently. The dockerization also facilitated easy deployment and scalability of the application.
All cameras were interconnected through a previously established local network, ensuring a seamless and high-speed transmission of video data to the server. This network infrastructure was critical in maintaining the real-time processing capabilities of the system.
Despite the initial success of the Proof of Concept (PoC), the application encountered challenges that necessitated further development:
- System Instability: The application occasionally experienced crashes, which were primarily attributed to the instability of the camera feeds. Interruptions or fluctuations in the video streams led to processing failures.
- Error Handling: The system needed improved mechanisms for handling errors and anomalies in video transmission and processing. This was essential to ensure continuous and reliable operation of the facility’s monitoring.
- Scalability Concerns: As the application was monolithic in nature, scaling specific components to handle increasing loads or to integrate additional features was a complex task.
The team recognized these challenges as part of the iterative development process. They provided valuable insights into the need for a more flexible, scalable, and robust system architecture, leading to the next stage of the project’s evolution.
Stage #2: Micro-servicesPermalink
In the progression of this IIoT project at the locomotive repair facility, the shift to a micro-services architecture was pivotal, particularly in addressing the unique challenges presented by the edge GPU server and the nature of IIoT systems dealing with external data flows:
- Video Stream Capture: This service focused on capturing live video feeds from facility cameras, crucial for real-time data processing on the edge GPU server, ensuring low latency in data handling.
- Image Aggregation: Responsible for processing video streams, this service handled frame extraction and image processing. Its role was vital in managing the high-volume data from IoT devices, optimizing the use of GPU resources for image analysis.
- Locomotive Position Estimator (LPE): Utilizing the edge computing capabilities, the LPE efficiently processed the camera feeds to determine locomotive positions, crucial for immediate data processing without the latency of cloud computing.
- Facility State Estimator (FSE): It synthesized data from various inputs, including the LPE, to create a dynamic overview of the facility, demonstrating the system’s ability to handle complex data flows from multiple IIoT sources.
Key Advantages in the Context of IIoT and Edge Computing:
- Scalability: The architecture’s scalability was enhanced by the ability to distribute processing tasks between the edge GPU server and cloud services, effectively managing the workload from numerous IoT devices.
- Resilience: The system’s resilience was bolstered by the distributed nature of micro-services, allowing for continuous operation even if one service experienced issues, a critical feature in the unpredictable environments of IIoT and edge computing.
- Efficient Data Management: The use of edge computing in conjunction with cloud services facilitated efficient data management, balancing immediate processing needs with long-term data storage and analysis.
- Enhanced Real-Time Processing: The micro-services architecture, combined with edge computing, enabled more efficient real-time processing of data, crucial for timely decision-making in the IIoT ecosystem.
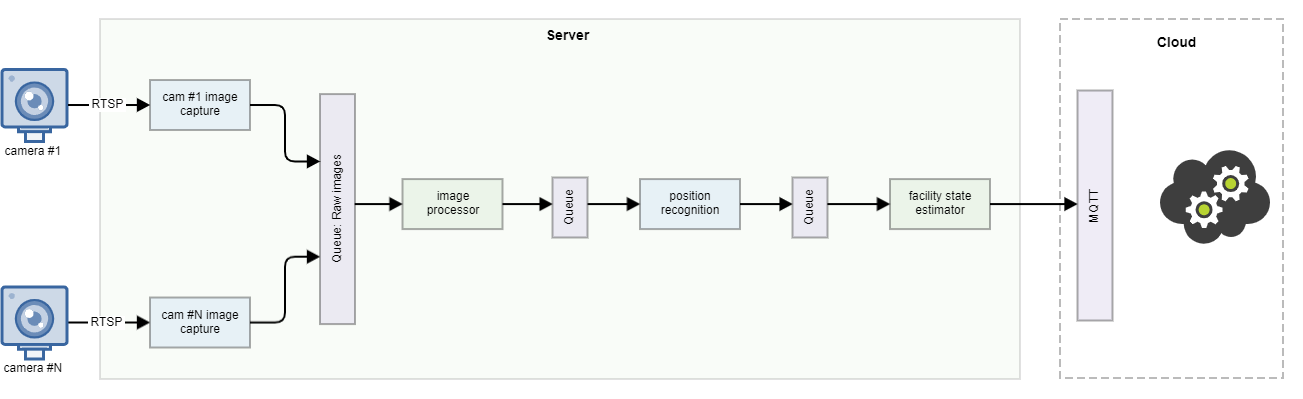
The communication between services was handled through advanced message/stream processing software like zeroMQ/imagezmq, rabbitMQ, and kafka (requiring external storage for images), ensuring efficient data flow across the system. This approach not only addressed the limitations of the initial monolithic structure but also effectively harnessed the capabilities of edge computing, making the system more adaptable and robust for the challenges of IIoT environments.
Stage #3: Development And Production Data FlowsPermalink
This stage focused on efficiently managing and utilizing the data generated by the micro-services, integrating it into a cloud solution for enhanced analysis and decision-making:
-
Cloud Integration and Storage: Data from the micro-services was sent to a cloud-based Time Series Database (TSDB), ideal for handling large-scale, time-sensitive data. This facilitated real-time analytics and was critical for effective data management.
-
Real-time Dashboards and Reporting: The cloud-stored data powered real-time dashboards and reports, providing immediate operational insights for quick decision-making and timely responses.
-
Enhanced Development Feedback Loop: Continuous improvement of the cloud solution, coupled with real-time data flow, allowed the development team to work with actual operational data, enhancing the feedback process with Business Analysts and Project Managers.
-
Service Stability: The initial services, video stream capture, and image processing, proved stable and required minimal adjustments, forming a reliable foundation for the data flow process.
-
Bifurcated Data Flow:
- Development Flow: Data was channeled through developmental versions of the Locomotive Position Estimator (LPE) and the Facility Position Estimator (FPE) for testing new updates in a controlled environment.
- Production Flow: Concurrently, the production flow used stable versions of the LPE and FPE, ensuring consistent service for operational needs.
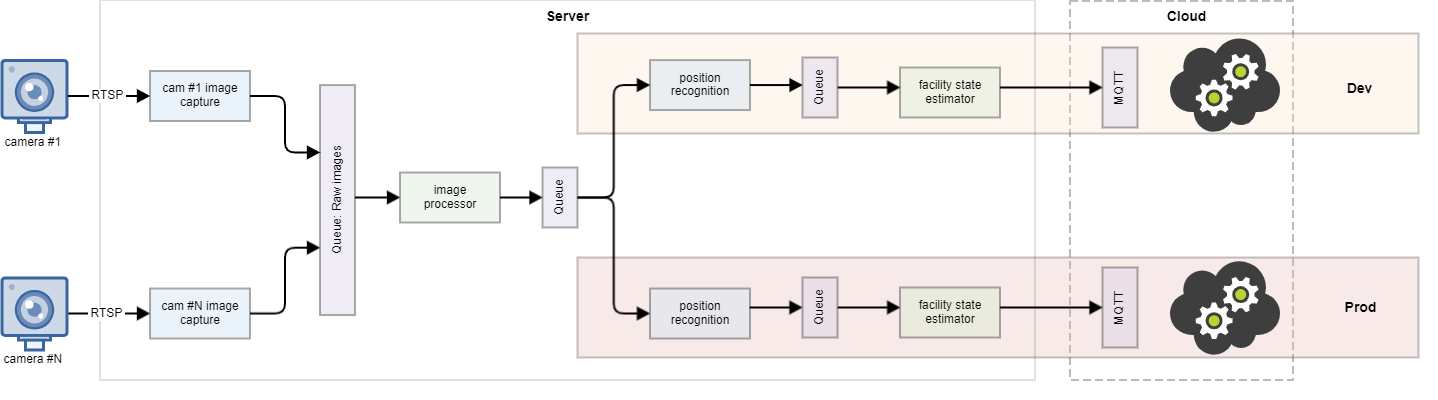
This dual-flow approach maintained production integrity while allowing continuous improvement and testing. The system’s scalable and adaptable design prepared it for future expansions and integrations, ensuring its long-term effectiveness in the dynamic setting of the locomotive repair facility.
Stage #4: ExtensibilityPermalink
This stage marked the system’s expansion to meet new operational demands:
-
New Informational Needs: With a stable data flow from the Facility State Estimator (FSE), Project Managers identified the need for more detailed data from the video streams. Specific requirements emerged for identifying locomotive models/types and ‘plate numbers’, crucial for enhancing operational management and maintenance planning.
- Development of Targeted Microservices:
- Locomotive Model Estimator: This service employed advanced image recognition techniques to determine locomotive models and types, aiding in logistical and maintenance decision-making.
- ‘Plate Number’ Recognizer: Focused on identifying and recording locomotives’ unique identification numbers, this service was key for tracking and optimizing facility workflow.
- Seamless Integration and Enhanced Reporting: These services were integrated with the existing microservices architecture, receiving data from image processors and feeding into the FSE. Their inclusion allowed for more detailed reporting, covering not only locomotive positions but also specific characteristics and identities.
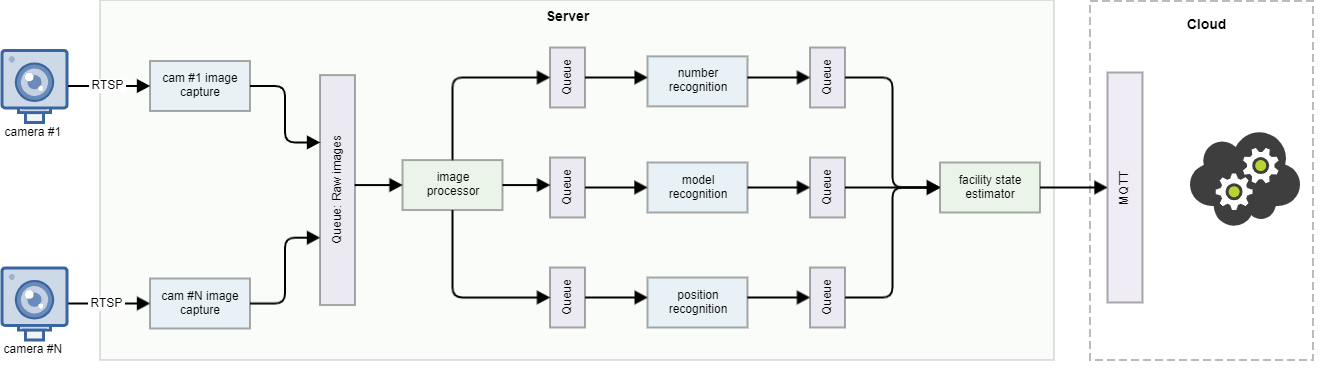
This phase showcased the system’s adaptability, enhancing its functionalities to address evolving requirements and setting the stage for future sophisticated applications.
ConclusionPermalink
Reflecting on the IIoT project at the locomotive repair facility, key insights include:
- Monolithic vs. Microservices Architecture:
- Early Stages: A monolithic app was effective for the initial Proof of Concept (PoC), simplifying development for analysts. It facilitated quick testing of basic functionalities like video stream capture and locomotive positioning.
- Scaling and Complexity: As the project’s complexity increased, a microservices architecture became crucial. This approach was more adaptable and scalable, essential for integrating advanced functions like the Locomotive Model Estimator and the ‘Plate Number’ Recognizer.
- IIoT Data Flow and Image Processing:
- Integration and Processing: The project highlighted the importance of integrating image processing into the IIoT data flow. Effective data capture and analysis were key for accurate state estimation of both individual locomotives and the entire facility.
- Advanced Applications: The use of advanced image processing and machine learning demonstrated the potential for such technologies in industrial settings, improving accuracy and operational efficiency.
- Adaptability and Future-Proofing:
- Evolving Requirements: The system’s adaptability to changing needs was crucial, as evidenced by the introduction of new services in later stages.
- Long-Term Viability: The evolution from a PoC to a sophisticated, microservices-based system underscores the importance of flexible, scalable, and adaptable digital solutions in industrial environments.
In summary, this IIoT project not only achieved its initial goals but also served as a model for digital transformation in industrial settings, demonstrating the necessity of adaptable, scalable, and technologically advanced solutions.


