
IntroductionPermalink
After facing some legacy systems lately and complains ‘sql db is bottleneck’ and ‘we have huge sql cluster’, usually accompanying with something like ‘we plan to switch to microservices’. Idea came up to my mind that somehow ‘microservices pattern’ is usually interpreted as separating ‘calculation’ or ’processing’ but not about data storage separation.
SQL database in legacy solution is usually used for storing and sometime processing of
- Business data
- ‘Stateful activity’
- Event logs (business, IoT, system)
- Business logic execution
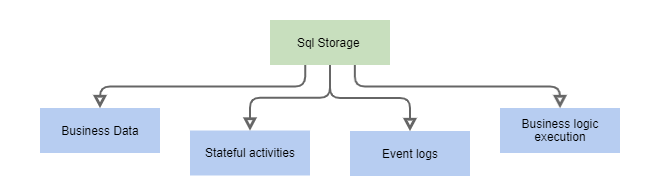
Let’s dive deeper into each scenario
Business domain dataPermalink
Business data – even though you can move it to some document storage that make sense sometime, just leave it there for now. There are usually better options to start optimization with.
Stateful activitiesPermalink
Any activity that will end up one day but needs some persistence till that happy moment. Usually it’s huge piece of work to do it in proper way but it looks pretty small until you dive deeper. Good new there are already solutions to handle all the heavy load.
- User interaction requests. When system needs some input from user. Common cases for enterprise solutions are all sorts of business process automation tasks (‘approve document’, ‘fulfill form’ etc.).
- Workflows (‘saga pattern’)
- Message queuing
- ETL artifacts. Some data is processed on regular basis and process is usually multistage, so intermediary results are stored in tables.
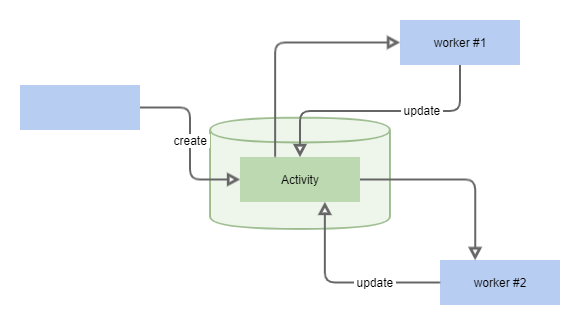
Common symptomsPermalink
- table that is constantly updating (number of update operations is significant) and ‘loosely coupled’ with other tables in DB
- table with ‘status’/‘processed’ field or ‘task’ in table name
| Scenario | Symptoms | Solutions | App examples |
|---|---|---|---|
| User interaction | tables refer to ‘user data’ table and in permanent update process | BPMS | Camunda |
| WF, sagas | check for common symptoms | Specialized WF solutions | Temporal, Cadence, Netflix Conductor |
| Queues | Look at solution code – one or several ‘workers’ is the key. | AMQP, Message bus | RabbitMq, Azure MessageBus |
| ETL | Same as queues (look for ‘workers’ in the code) but tables usually contains bigger records | Build datapipe or use actor approach for ‘stateful serverless’ | Airflow, Luigi vs AKKA, Orleans |
Event logsPermalink
Journals of ‘actual events’ that are not always well structured.
- IoT/IIoT data. User interacts with some hardware and you log this event or some device’s sensor sends data system – think about it as IoT-data-streams and handle these events in ‘modern way’
- Business events. External system is generates data that needs to be processed
- System, application, solution events, user UI interaction events etc.
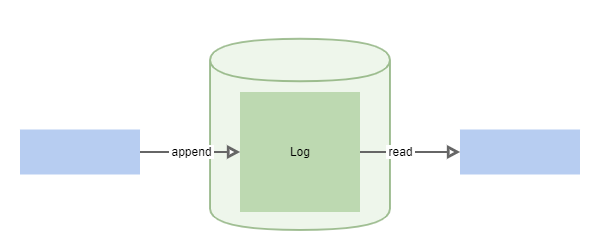
Common symptomsPermalink
- huge (in terms of number of rows) tables that constantly growing with no links to other tables
- ‘append only’ tables that periodically cleaned up (mostly manually)
| Scenario | Solution | App examples |
|---|---|---|
| IoT | *simple processing | MongoDb, Kafka, Clickhouse |
| Business events | *simple processing | MongoDb, MessageBus, Data Warehouse |
| System events | Logging solutions | ELK, Prometheus |
*Simple processingPermalink
- Store raw incoming events in NoSql Db (MongoDB) with TTL
- Create data-pipe to process them (Airflow, Luigi, Spark) or go with RabbitMQ and console-apps
- Save consumable results in Data Warehouse or OLAP-friendly DB (Clickhouse)
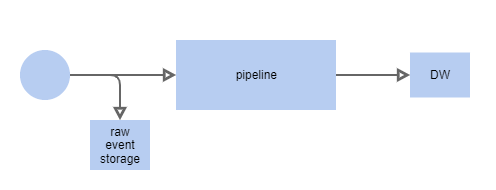
Check ‘stream processing’ approaches, but it might be too much at this stage.
Stored procedures and triggersPermalink
Last but not the least. You have tons of stored procedures and triggers, in other words lots of solutions business logic leaves there
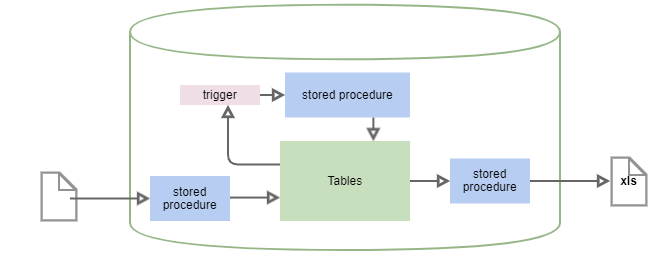
| Component | Example | Solution |
|---|---|---|
| Triggers | Start ‘next step’ of processing after ‘status’ is changed | check ‘stateful activities’ part of this article |
| Heavy aggregating procedures | Generating reports or spreadsheets for export | check datapipes |
| Scheduled heavy updating procedures | Monthly salary payments in big enterprise | BPMS/WF and/or immutable data pattern |
(Very opinionated) usually lot’s stored procedures and/or triggers is pure evil.
ConclusionPermalink
There are definitely more cases of using SQL DBs and other persistence approaches than mentioned in this short article. Nothing wrong to use DB for all the things mentioned above, but there are special solutions to handle these tasks with
- More functionality. Even if don’t need it now, it’s like a good old hammer – you’ll see many nails around.
- Better tested, production ready and better optimized
- Community to support and developers to find


